![]()
在 NUMA (Non-uniform memory access) 架構下,如何知道記憶體的存取效能如何,Intel 提供了 Memory Latency Checker 可以做檢查.下載點 https://software.intel.com/en-us/articles/intelr-memory-latency-checker#inpage-nav-9
測試環境為 CentOS7 x86_64
什麼是 NUMA ?
多核心的處理器最早是透過對稱多處理 SMP (Symmetric multiprocessing) 的方式,所有的 CPU 核心對於記憶體的存取是共用的,但是當 CPU 核心數太多時反而是一個限制,當不同的處理器需要交換資料時都是透過系統匯流排將資料儲存在記憶體中,但當核心數多時,交換資料變成常態, CPU 與記憶體之間的速度跟不上 CPU 處理的速度.越多的核心反而讓整體效能降低.
因此有了 Intel 的 NUMA (Non-uniform memory access),他把 CPU 與記憶體區分成不同的結點 Node (不同的 CPU 各自擁有記憶體),彼此的 CPU 節點再透過 QPI (Intel QuickPath Interconnect) , UPI(Ultra Path Interconnect) 這個介面做溝通.
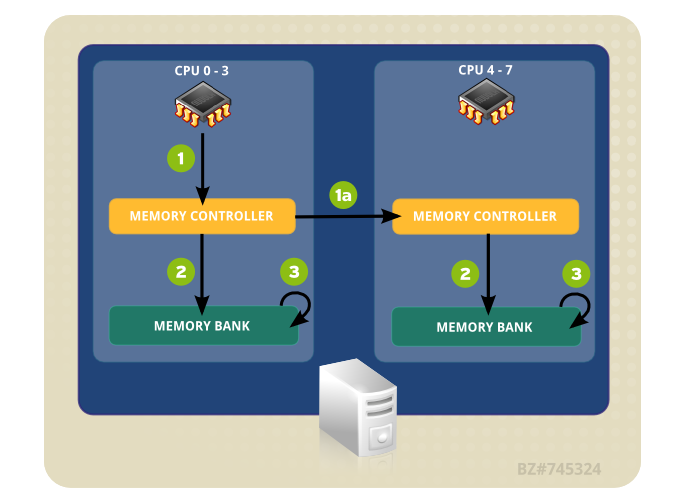
圖片出自於 https://access.redhat.com/documentation/zh-tw/red_hat_enterprise_linux/6/html/performance_tuning_guide/main-cpu
NUMA 裝態可以透過 numactl , numastat 兩支程式來檢視與應用,詳細說明請參考 https://benjr.tw/96788
MLC 下載解開就可以直接執行了.
[root@localhost ~]# tar zxvf mlc_v3.5.tgz [root@localhost ~]# cd Linux/ [root@localhost Linux]# ./mlc -help Intel(R) Memory Latency Checker - v3.5 Invalid Argument:-help USAGE: Default and recommended usage is to just run the binary "./mlc". For specific analysis, there are f ./mlc --latency_matrix prints a matrix of local and cross-socket memory latencies ./mlc --bandwidth_matrix prints a matrix of local and cross-socket memory bandwidths ./mlc --peak_injection_bandwidth prints peak memory bandwidths of the platform for various ./mlc --idle_latency prints the idle memory latency of the platform ./mlc --loaded_latency prints the loaded memory latency of the platform ./mlc --c2c_latency prints the cache to cache data transfer latency of the platform ...
latency_matrix
直接使用預設的參數來執行記憶體的延遲 (Latency).
[root@localhost Linux]# ./mlc --latency_matrix
Intel(R) Memory Latency Checker - v3.5
Command line parameters: --latency_matrix
Using buffer size of 2000.000MB
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1
0 101.6 150.8
1 150.8 101.6
執行結果
- Node0 CPU 存取 Node0 Memory 延遲為 101.6 ns
- Node1 CPU 存取 Node0 Memory 延遲為 150.8 ns
透過指令 #numactl 觀察程式 MLC 執行時,會發現 other_node 有增加的現象(該節點上的程序,成功配置到另一個節點的記憶體空間),代表兩個處理器的 QPI (UPI) 有進行傳輸. - Node0 CPU 存取 Node1 Memory 延遲為 150.8 ns
透過指令 #numactl 觀察程式 MLC 執行時,會發現 other_node 有增加的現象(該節點上的程序,成功配置到另一個節點的記憶體空間),代表兩個處理器的 QPI (UPI) 有進行傳輸. - Node1 CPU 存取 Node1 Memory 延遲為 101.6 ns
bandwidth_matrix
直接使用預設的參數來執行記憶體的頻寬 (bandwidth)
[root@localhost Linux]# ./mlc --bandwidth_matrix
Intel(R) Memory Latency Checker - v3.5
Command line parameters: --bandwidth_matrix
Using buffer size of 100.000MB/thread for reads and an additional 100.000MB/thread for writes
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0 1
0 91278.4 46050.8
1 46079.1 91402.1
執行結果
- Node0 CPU 存取 Node0 Memory 頻寬為 91278.4 MB/sec
- Node1 CPU 存取 Node0 Memory 頻寬為 46079.1 MB/sec
- Node0 CPU 存取 Node1 Memory 頻寬為 46050.8 MB/sec
- Node1 CPU 存取 Node1 Memory 頻寬為 91402.1 MB/sec
其他參數:
peak_injection_bandwidth
Using buffer size of 100.000MB/thread for reads and an additional 100.000MB/thread for writes
idle_latency
Each iteration took # core clocks ( # ns).
loaded_latency
Using buffer size of 100.000MB/thread for reads and an additional 100.000MB/thread for writes
c2c_latency
Measuring cache-to-cache transfer latency (in ns)…