![]()
測試環境為 CentOS 8 x86_64 (虛擬機)
如何透過 Python 套件將文章內容自動加 Tag(標籤) , 參考文章 – https://www.analyticsvidhya.com/blog/2022/01/four-of-the-easiest-and-most-effective-methods-of-keyword-extraction-from-a-single-text-using-python/ , 或是官網 – https://github.com/MaartenGr/KeyBERT
下面使用 KeyBert 套件來試試看.
安裝 KeyBert 套件前先更新 pip3 並安裝 setuptools_rust 套件.
[root@localhost ~]# pip3 install --upgrade pip [root@localhost ~]# pip3 install setuptools_rust
[root@localhost ~]# pip3 install keybert
[root@localhost ~]# python3 Python 3.6.8 (default, Jun 23 2022, 19:01:59) [GCC 8.5.0 20210514 (Red Hat 8.5.0-13)] on linux Type "help", "copyright", "credits" or "license" for more information.
準備要自動加 Tag(標籤) 的文章內容.
title = "VECTORIZATION OF TEXT USING DATA MINING METHODS"
text = "In the text mining tasks, textual representation should be not only efficient but also interpretable, as this enables an understanding of the operational logic underlying the data mining models. Traditional text vectorization methods such as TF-IDF and bag-of-words are effective and characterized by intuitive interpretability, but suffer from the «curse of dimensionality», and they are unable to capture the meanings of words. On the other hand, modern distributed methods effectively capture the hidden semantics, but they are computationally intensive, time-consuming, and uninterpretable. This article proposes a new text vectorization method called Bag of weighted Concepts BoWC that presents a document according to the concepts’ information it contains. The proposed method creates concepts by clustering word vectors (i.e. word embedding) then uses the frequencies of these concept clusters to represent document vectors. To enrich the resulted document representation, a new modified weighting function is proposed for weighting concepts based on statistics extracted from word embedding information. The generated vectors are characterized by interpretability, low dimensionality, high accuracy, and low computational costs when used in data mining tasks. The proposed method has been tested on five different benchmark datasets in two data mining tasks; document clustering and classification, and compared with several baselines, including Bag-of-words, TF-IDF, Averaged GloVe, Bag-of-Concepts, and VLAC. The results indicate that BoWC outperforms most baselines and gives 7% better accuracy on average"
full_text = title +", "+ text
print("The whole text to be usedn",full_text)
匯入 KeyBERT 套件
from keybert import KeyBERT
下面選擇效率最好的模組 all-mpnet-base-v2 , KeyBERT 提供多種模組其敘述請參考官方網站說明 – https://www.sbert.net/docs/pretrained_models.html
kw_model = KeyBERT(model='all-mpnet-base-v2')
開始分析.
keywords = kw_model.extract_keywords(full_text, keyphrase_ngram_range=(1, 3), stop_words='english', highlight=True , top_n=10)
其中參數
- keyphrase_ngram_range=(1, 3)
選擇的關鍵字字數 , (1,3) 為 1 ~ 3 個字. - highlight=True
用來凸顯關鍵字, True 為凸顯, False 則非. - top_n=10
顯示前幾名的關鍵字,如果要全部顯示則使用 top_n=0 .
執行結果
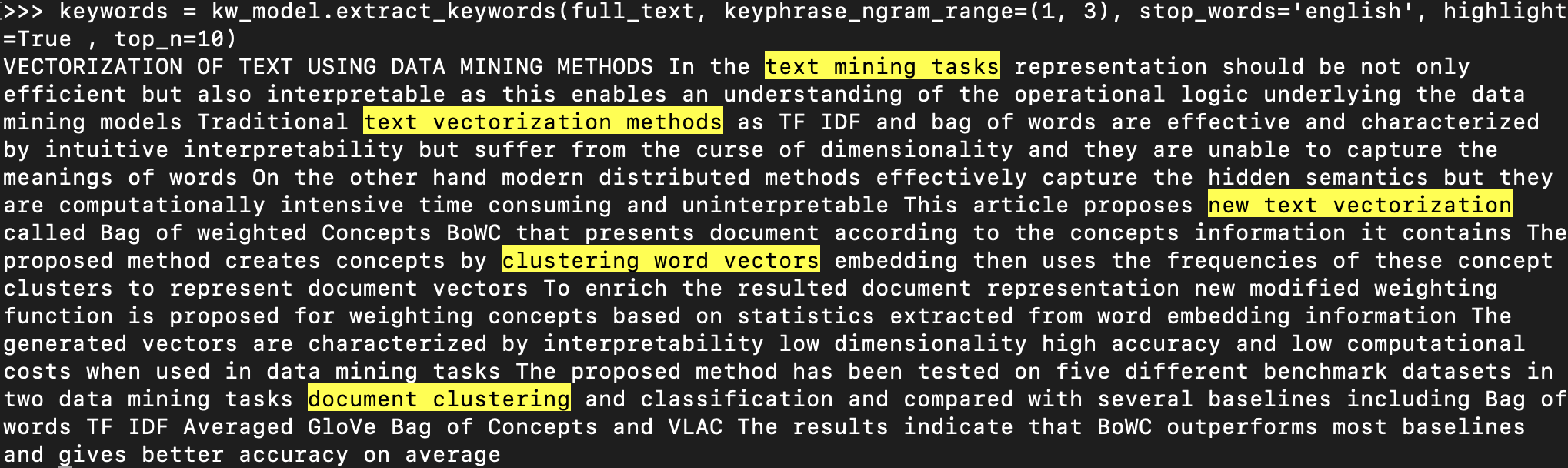
回傳值為 list 物件.
>>> keywords
[('document clustering classification', 0.619), ('clustering word vectors', 0.5884), ('text vectorization method', 0.5622), ('document clustering', 0.5604), ('text vectorization methods', 0.558), ('text vectorization', 0.5564), ('text mining', 0.5537), ('new text vectorization', 0.5497), ('text mining tasks', 0.5426), ('methods text mining', 0.5331)]
如需將結果轉成 Json 字串 (String) ,可以透過 json 模組的功能來轉換,關於 json 模組使用請參考 – https://benjr.tw/104718 .
>>> import json
>>> keywords_list=json.dumps(dict(keywords) , indent=4)
>>> print(keywords_list)
{
"document clustering classification": 0.619,
"clustering word vectors": 0.5884,
"text vectorization method": 0.5622,
"document clustering": 0.5604,
"text vectorization methods": 0.558,
"text vectorization": 0.5564,
"text mining": 0.5537,
"new text vectorization": 0.5497,
"text mining tasks": 0.5426,
"methods text mining": 0.5331
}
遇過的錯誤
透過 pip 安裝 KeyBert 套件時,出現以下錯誤訊息.
Q1:
Collecting zipp>=0.5
Downloading zipp-3.6.0-py3-none-any.whl (5.3 kB)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/lib/python3.6/site-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (3.0.4)
Requirement already satisfied: idna<2.8,>=2.5 in /usr/lib/python3.6/site-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (2.5)
Requirement already satisfied: urllib3<1.25,>=1.21.1 in /usr/lib/python3.6/site-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (1.24.2)
Requirement already satisfied: six in /usr/lib/python3.6/site-packages (from sacremoses->transformers<5.0.0,>=4.6.0->sentence-transformers>=0.3.8->keybert) (1.11.0)
Using legacy 'setup.py install' for sentence-transformers, since package 'wheel' is not installed.
Using legacy 'setup.py install' for sacremoses, since package 'wheel' is not installed.
Installing collected packages: zipp, typing-extensions, pyparsing, importlib-resources, importlib-metadata, tqdm, regex, pyyaml, packaging, numpy, joblib, filelock, dataclasses, click, torch, tokenizers, threadpoolctl, scipy, sacremoses, pillow, huggingface-hub, transformers, torchvision, sentencepiece, scikit-learn, pygments, nltk, commonmark, sentence-transformers, rich, keybert
Attempting uninstall: pyyaml
Found existing installation: PyYAML 3.12
ERROR: Cannot uninstall 'PyYAML'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
需使用 –ignore-installed 安裝 PyYAML 套件.
[root@localhost ~]# pip3 install --ignore-installed PyYAML Collecting PyYAML Using cached PyYAML-6.0-cp36-cp36m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (603 kB) Installing collected packages: PyYAML Successfully installed PyYAML-6.0
Q2:
Downloading https://files.pythonhosted.org/packages/12/57/da0cb8e40437f88630769164a66afec8af294ff686661497b6c88bc08556/tokenizers-0.12.1.tar.gz (220kB)
100% |████████████████████████████████| 225kB 4.1MB/s
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-build-pjtqxwc_/tokenizers/setup.py", line 2, in <module>
from setuptools_rust import Binding, RustExtension
ModuleNotFoundError: No module named 'setuptools_rust'
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-pjtqxwc_/tokenizers/
需安裝 setuptools_rust 套件.
[root@localhost ~]# pip3 install setuptools_rust
沒有解決問題,試試搜尋本站其他內容