![]()
ETCD2 Cluster members
- CoreOS1 (Node1) , IP: 172.16.15.21 (Leader)
- CoreOS2 (Node2) , IP: 172.16.15.22
- CoreOS3 (Node3) , IP: 172.16.15.23
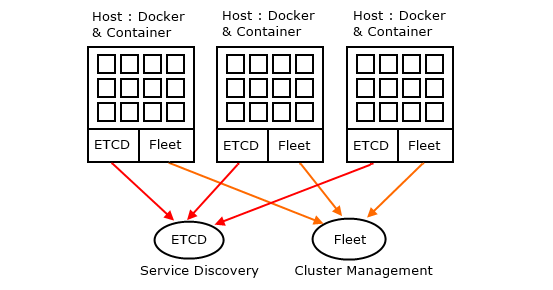
有 3 個 node 的 Cluster 就具備了容錯的功能.
3 CLUSTER SIZE ,2 MAJORITY , 1 FAILURE TOLERANCE
可以允許一個 Node 的錯誤.
其他多個 Node 的 Cluster 的 SIZE ,MAJORITY, FAILURE TOLERANCE CLUSTER 容錯功能請參考 https://coreos.com/etcd/docs/latest/v2/admin_guide.html#optimal-cluster-size
etcd2 的設定請參考 關於
- etcd2 設定與使用方式 – https://benjr.tw/96404
- 新增/移除 etcd2 Node – https://benjr.tw/96449
來試試看,一開始 etcd2 狀態都是正常的
core@coreos1 ~ $ etcdctl member list 29df81d17418132: name=node01 peerURLs=http://172.16.15.21:2380 clientURLs=http://172.16.15.21:2379 isLeader=true 48852466e20da1b8: name=node03 peerURLs=http://172.16.15.23:2380 clientURLs=http://172.16.15.23:2379 isLeader=false e1c17ca056760d6d: name=node02 peerURLs=http://172.16.15.22:2380 clientURLs=http://172.16.15.22:2379 isLeader=false
core@coreos1 ~ $ etcdctl cluster-health member 29df81d17418132 is healthy: got healthy result from http://172.16.15.21:2379 member 48852466e20da1b8 is healthy: got healthy result from http://172.16.15.23:2379 member e1c17ca056760d6d is healthy: got healthy result from http://172.16.15.22:2379 cluster is healthy
接下來把 Node3 關閉.
core@coreos1 ~ $ etcdctl cluster-health member 29df81d17418132 is healthy: got healthy result from http://172.16.15.21:2379 failed to check the health of member 48852466e20da1b8 on http://172.16.15.23:2379: Get http://172.16.15.23:2379/health: dial tcp 172.16.15.23:2379: i/o timeout member 48852466e20da1b8 is unreachable: [http://172.16.15.23:2379] are all unreachable member e1c17ca056760d6d is healthy: got healthy result from http://172.16.15.22:2379 cluster is healthy
可以很清楚知道 Node3 的狀態已經是 unreachable 的.但 cluster 的狀態是 healthy 的.
接下來把 Node2 也關閉.
core@coreos1 ~ $ etcdctl cluster-health member 29df81d17418132 is unhealthy: got unhealthy result from http://172.16.15.21:2379 failed to check the health of member 48852466e20da1b8 on http://172.16.15.23:2379: Get http://172.16.15.23:2379/health: dial tcp 172.16.15.23:2379: i/o timeout member 48852466e20da1b8 is unreachable: [http://172.16.15.23:2379] are all unreachable failed to check the health of member e1c17ca056760d6d on http://172.16.15.22:2379: Get http://172.16.15.22:2379/health: dial tcp 172.16.15.22:2379: i/o timeout member e1c17ca056760d6d is unreachable: [http://172.16.15.22:2379] are all unreachable cluster is unhealthy
Node2 的狀態也變成 unreachable 的.連 Node1 的狀態也變成了 unhealthy, cluster 狀態也是 unhealthy. 3個 Node 最多只能支援 1 個 Node 的錯誤.
要恢復 etcd2 Cluster 的狀態可以參考 etcd2 的災難復原 – https://benjr.tw/96497
沒有解決問題,試試搜尋本站其他內容
3 thoughts on “CoreOS etcd2 Cluster 的容錯能力”