![]()
老實說一開始我也搞不清楚什麼是 Hadoop ,應該是跟雲端有關,但是 Hadoop 是做什麼的呢!!為什麼這麼多公司會應用到他呢!!!
看到目前為止我想他是 "分散式運算 (MapReduce)" + " 叢聚式檔案系統 Hadoop Distributed File system(HDFS) or Global File System (GFS)" + "資料庫系統 (HBase)" ,所以可以把他歸類在 PaaS (platform as a service) 提供雲端平台的服務那一層!!
Hadoop 其實是 Apache 的專案總稱,從下圖是可以很清楚知道 Hadoop 專案是由好幾個子集 (Hadoop Common, HDFS , MapReduce, HBase) 所構成的,後面可以看到較多的詳細多說明

- Hadoop Common:
首先是 Hadoop Common 裏面具備了支援其他子集的常用工具. - MapReduce
使用不同的節點來處理同一件事,最後再將資料重整,亦即所謂的平行式處理. - HDFS (Hadoop Distributed File system)
資料的儲存不再是單一節點式的儲存,分散的儲存帶來的好處是可以高速讀取資料並確保不因單一節點故障而使資料遺失.
我們還是先從 Hadoop wiki 或是 Hadoop Apache 的官方網站來閱讀何謂 Hadoop (不過目前資料還是以英文為主)
- Hadoop wiki
從 wiki 對於 Hadoop 的說明第一句話是 "Apache Hadoop is a software framework that supports data-intensive distributed applications under a free license" 也就是 Hadoop 為 Apache 下的開放原始碼,他可應用在分散式檔案系統的運算 (MapReduce) 與儲存(HDFS). - Hadoop Apache
The Apache™ Hadoop™ project develops open-source software for reliable, scalable, distributed computing.
Hadoop 為 Apache 下的開放原始碼,他為一套高可靠度且具延展現的分散式運算.The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using a simple programming model.
這開放原始碼主要的目的是為了要處理叢集電腦的大量資料.
下圖是 Hadoop 的架構圖.

現在來看看 Hadoop 個別的子集是負責哪些工作.
Hadoop MapReduce:
傳統我們在處理資料時,是將資料讀入電腦經由處理器的處理然後再將分析過的資料輸出給使用者,如果資料量小時沒太大的問題,你的個人電腦就可以處理完畢,但當資料大且需要花費大量時間來處理的資料,相信一台的個人電腦是處理不來,此時該怎麼辦呢!!!(雖然有所謂的超級電腦,但我也沒有實際接觸過所以不討論).
那什麼時候需要大量的運算呢,如 Google 的搜尋他需要處理的資料量大而且必須要在短時間內回應給使用者,此時分散式資料系統就派得上用場了,分散式的資料處理你可以它想像成,需要處理的資料會先經過切割處理,變成多份小型的資料然後再分散給多台電腦來處理.處理完畢再回收所有的資料,這就是 MapReduce 所要做的事情.
回到 MapReduce 的分散式資料處理,跟大多數的分散式系統一樣主要也是分成為 2 個工作,第一步就是透過 Map 將要運算的資料切割成多塊並將他們分散到不同的電腦來處理,而 Reduce 就是收回由不同電腦處理好的資料並將他彙整成為一份資料給使用者.
有人以更生活化的方式來比喻 MapReduce ,他就如同全國性的選舉,首先我們會在全國各地設置投開票所 (等同 Map 的功能將要處理的資料分散各不同電腦來處理),等待所有的人來投票 (資料輸入),接下來各個投開票所統計自己的開票結果,並回傳到中選會的投開票資料中心 (Reduce),等所有的投開票中心都算完票數就可以得到開票的結果了!!
當然我們還是來看看實際上 MapReduce 是怎麼運作的,透過網路查詢 MapReduce 時,最常查詢到兩種用以說明 Map 與 Reduce 的運作模式.不過我覺得把這兩張圖同時來看就會很清楚 MapReduce 的架構與運作方式.
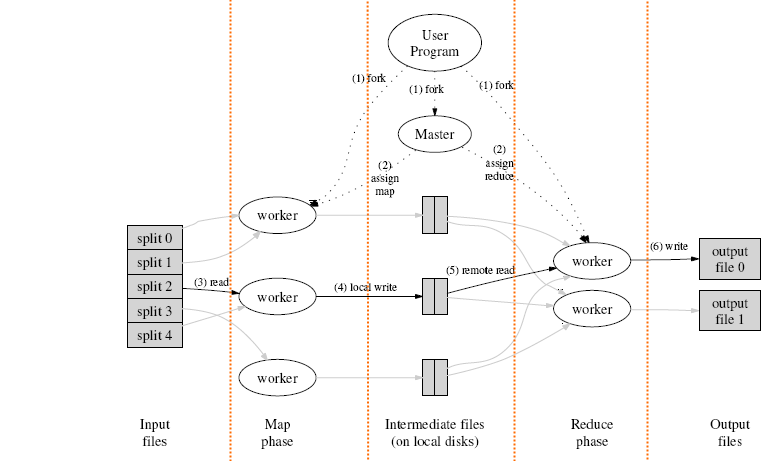
我尚未開始接觸到 Hadoop 的程式寫作,目前所書寫的流程是參考了多份文件所寫成(目前只想得知 Hadoop 的概念),或許我開始寫 Hadoop 成是這一部分可能會再做修改. 從上圖可以看到有步驟順戲我就按著步驟一一說明.
- 由 User Program (Process)所產生 (fork) 的新的子行程到 Master(由他來管控哪一 Map 以及 Reduce 是由誰來處理)
- 由 Master 指派 Map 以及 Reduce 是由哪一個 worker(電腦) 來處理.User Program 也會複製到每一臺 Map / Reduce 的 Worker 中.
- 檔案再處理前就會先行切割成大小適中的小檔案,並交由不同的 Map Worker 來處理,要做怎麼樣的處理是依據 User Program(後面我們會看到統計字串的實際案例).
- 並將處理得到的結果先暫時儲存在 Map worker 本地端的儲存裝置.
- 再由 Reduce worker 來讀取剛剛 Map worker 暫存在該 work 本地端的資料,並繼續進行我們設計好的 User Program 來處理
- 最後由 Reduce worker 儲存到遠端的 HDFS(分散式檔案系統) 才大功告成.
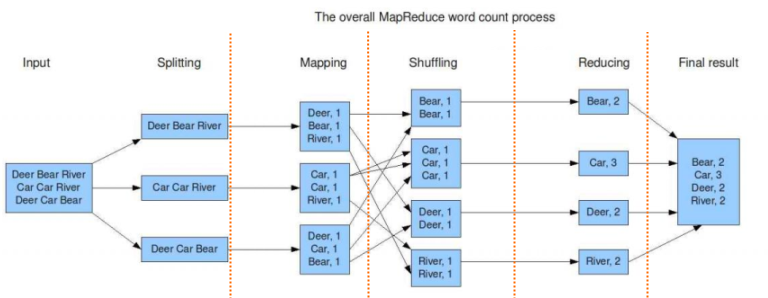
上面這個範例是以 Hadoop 的 MapReduce 為基礎統計出一篇文章內的單字出現次數,由 Hadoop 英文版 wiki 所翻譯而來的
- 資料讀取與分割
我們假設的資料量很大,當如不是如上面的文章單單就幾行而已,通常資料會被分割成小量的資料 (通常大小為 16 MB 至 128 MB) 系統會指派不同的資料給不同的系統來運算.當然此案例的資料量很小不過還是以 MapReduce 的方式將檔案切割成設和的大小來運作. - Map function
每個 worker 收到資料後會將處理把它處理程 (key , value) 的方式,以方便未來適合做統計. - Reduce function
每一個 Reduce worker 會去接收不同 Map worker 所產生的資料,不同的 Reduce worker 會去處理不同的 Key .Reduce worker 會開始統計出所產生的字串有多少個. - Output writer
最後階段就是將資料回寫到儲存裝置,通常就是分散式儲存系統( Distributed File System),在 Hadoop 是使用 HDFS.
當然目前寫的我也看不是很懂,未來會持續修改中!!!
Hadoop Distributed File System (HDFS):
分散式系統可以高速的處理資料,所以在選擇儲存裝置上也必須相對應的高速但如何在價錢與速度中間取得平衡點,也因此 Hadoop 不採取傳統的高速儲存裝置,他採用另一種高效能的分散檔案系統來儲存大型資料.那何謂分散式的檔案系統???
再開始討論分散式檔案系統前我們現在回顧一下 Linux 下的檔案儲存是採用什麼方式,他採用了 superblock / inode /data block 的方式來儲存資料.
- data block
資料在儲存時不太可能每一次都有連續的空間可供資料的儲存,所以資料會切割成固定大小分開存放,這大小的空間就是 data block 但在談 data block 大小前,先來說說硬碟的儲存最小單位 block size ,通常硬碟在出廠前都先經過低階格式化,而預設的大小就是 512bytes , 但512bytes 真的太小所以在 Linux 下我們用的是另外一種單位就是 data block ,而他的大小必須為 512bytes 的倍數. 512,1024,2048,4096 bytes 通常在 Linux 下為 4096bytes.Data, Data block 與 block 的相關如下所是.Data –> Data block(s) –> block(s)
- inode
剛剛說到 data block 的資料是一塊塊分散的儲存(索引式檔案系統),所以此時必須要一塊資料要紀錄哪些 data block 是屬於哪一個 data 的, 而記錄了這些資料的就叫做 inode ,每一個檔案都會對應到一個 inode 他的大小為 128bytes 除了紀錄 data block 的位置外還儲放了檔案的權限與相關屬性. - superblock
那剛剛 inode/block 的使用情況(使用量,剩餘…)是由誰來紀錄,就是透過 superblock 基本上他記錄該檔案系統所有的資訊. 所以我們可以很清楚了解 superblock / inode / data block 的關係.superblock –>inode –> data block
更多有關於 Linux 的檔案系統建議可以參 鳥哥的 Linux 私房菜 – 第八章、Linux 磁碟與檔案系統管理
好現在回到 Hadoop 的 HDFS,HDFS 的資料儲存方式跟這很類似,不過最大的不同點是 data block 的資料是分散跨越在不同的機台上.先說兩個名稱 Namenode 以及Datanodes
- Namenode
Namenode 的角色就類似於 Linux 檔案系統下的 inode ,他會將檔案切割成固地大小的 Block, 並將這些資料儲存到不同的 Datanode,並同時記錄他們的所在. - Datanodes
這就是資料儲存的單位,類似 Linux 系統下的 Data block,為了資料的安全性 資料的儲存預設至少會有 3 個副本(Replication),而這些副本通常會跨在不同機台上. 這樣設計的好處是資料在讀取時可以同時讀取不同的機台的 DataNode 藉此方式高速的取得檔案,也不會因為單一 DataNode 消失而無法讀取資料.
下圖你可以看到 Namenode 是儲存了哪一些資料,以及 Datanodes 的儲存方式.
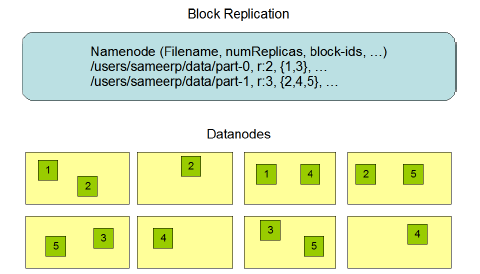
namenode (Filename, numReplicas, block-ids,…)
/users/sameerp/data/part-0,r:2,{1,3},…
/users/sameerp/data/part-1,r:3,{2,4,5},…
至於 HDFS 資料的讀寫可以參考如下:
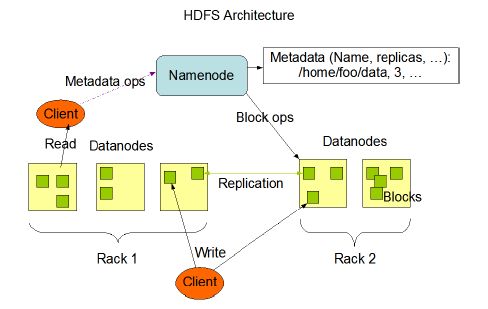
圖片出自於 http://hadoop.apache.org
Hbase:
在 Hadoop 1.0 的版本加入了 Hbase ,這跟資料庫相關.
最後我們來複習一下剛剛零零亂亂關於 Hadoop 的 MapReduce 以及 HDFS 到底講了什麼,我們可以看下面這一張圖

你會很清楚的了解到 最底程的 HDFS Layer 是負責做資料儲存的,Master 會有 name node(資料儲存的索引) 以及 datanode(區塊資料) 的存在而 slave 只會有 datanode 的存在.
MapReduce Layer 的工作是負責將資料分散處理再重組,在 Master 會有 Task tracker 與 job tracker ,而 Slave 只有 task tracker.Job tracker 就是負責將使用者程式送給目前有用的 Task Tracker 來處理.
瞭解了 Hadoop 的概念我們可以開始架設 Hadoop 了,但第一步要怎麼開始呢!!!雖然我們可以在網路上找到很多相關的說明,不過還是從 Apcahe 的官方網站的 Getting Started 開始架設 Hadoop 吧!!!
或是我整理的 Hadoop – Getting Started
寫這一份時參考了很多文件
~.:.': .NET碎碎念:'.':.~
StackDoc
這一份文件檔說明得很清楚可以拿來參考!!